Example for cistrome imputation using prompt-enhanced ChromBERT¶
ChromBERT’s context-specific TRN embeddings can be used to impute cell-type-specific cistromes through prompt engineering. In this tutorial, we demonstrate how to impute cistromes for a given cell type using ChromBERT. The model has been trained with two types of prompts: DNase-seq prompts from ChromBERT and RNA-seq prompts from scGPT. Pre-trained model checkpoints are available on Huggingface.
To follow this tutorial, you will need to download the checkpoint files (see the Installation Guide for details).
Attention: You should go through thistutorialat first to get familiar with the basic usage of ChromBERT.
[1]:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # to selected gpu used
import sys
import pathlib
import pickle
import torch
import numpy as np
import pandas as pd
from tqdm import tqdm
from matplotlib import pyplot as plt
import seaborn as sns
import chrombert
from torchinfo import summary
import lightning.pytorch as pl
import sklearn
import sklearn.metrics
basedir = os.path.expanduser("~/.cache/chrombert/data" )
/home/yangdongxu/.local/lib/python3.10/site-packages/pandas/core/arrays/masked.py:60: UserWarning: Pandas requires version '1.3.6' or newer of 'bottleneck' (version '1.3.5' currently installed).
from pandas.core import (
Cistrome-prompt enhanced ChromBERT¶
chrombert.get_preset_model_config(...,dropout=0.1) to enable dropout during training, and set finetune_ckpt=None to start from the pretrained checkpoint.prepare model¶
[2]:
mc = chrombert.get_preset_model_config("prompt_cistrome", dropout = 0)
model = mc.init_model().cuda().bfloat16().eval()
mc
update path: pretrain_ckpt = checkpoint/hg38_6k_1kb_pretrain.ckpt
update path: finetune_ckpt = checkpoint/hg38_6k_1kb_prompt_cistrome.ckpt
use organisim hg38; max sequence length is 6391
Loading checkpoint from /home/yangdongxu/.cache/chrombert/data/checkpoint/hg38_6k_1kb_prompt_cistrome.ckpt
Loading from pl module, remove prefix 'model.'
Loaded 112/112 parameters
[2]:
ChromBERTFTConfig:
{
"genome": "hg38",
"task": "prompt",
"dim_output": 1,
"mtx_mask": null,
"dropout": 0,
"pretrain_ckpt": "/home/yangdongxu/.cache/chrombert/data/checkpoint/hg38_6k_1kb_pretrain.ckpt",
"finetune_ckpt": "/home/yangdongxu/.cache/chrombert/data/checkpoint/hg38_6k_1kb_prompt_cistrome.ckpt",
"ignore": false,
"ignore_index": [
null,
null
],
"gep_flank_window": 4,
"gep_parallel_embedding": false,
"gep_gradient_checkpoint": false,
"gep_zero_inflation": false,
"prompt_kind": "cistrome",
"prompt_dim_external": 768,
"dnabert2_ckpt": null
}
prepare dataset¶
[3]:
summary(model)
[3]:
================================================================================
Layer (type:depth-idx) Param #
================================================================================
ChromBERTPrompt --
├─ChromBERT: 1-1 --
│ └─BERTEmbedding: 2-1 --
│ │ └─TokenEmbedding: 3-1 7,680
│ │ └─PositionalEmbedding: 3-2 4,909,056
│ │ └─Dropout: 3-3 --
│ └─ModuleList: 2-2 --
│ │ └─EncoderTransformerBlock: 3-4 6,497,280
│ │ └─EncoderTransformerBlock: 3-5 6,497,280
│ │ └─EncoderTransformerBlock: 3-6 6,497,280
│ │ └─EncoderTransformerBlock: 3-7 6,497,280
│ │ └─EncoderTransformerBlock: 3-8 6,497,280
│ │ └─EncoderTransformerBlock: 3-9 6,497,280
│ │ └─EncoderTransformerBlock: 3-10 6,497,280
│ │ └─EncoderTransformerBlock: 3-11 6,497,280
├─PromptsEmb: 1-2 --
│ └─Pooling: 2-3 --
├─PromptHeader: 1-3 --
│ └─Sequential: 2-4 --
│ │ └─ResidualBlock: 3-12 10,626,048
│ │ └─ResidualBlock: 3-13 4,132,608
│ │ └─ResidualBlock: 3-14 1,182,720
│ │ └─ResidualBlock: 3-15 102,720
│ │ └─Linear: 3-16 65
================================================================================
Total params: 72,939,137
Trainable params: 72,939,137
Non-trainable params: 0
================================================================================
[4]:
table_peak = os.path.join(basedir, "demo","prompt_imputation", "MAZ_K562_narrowPeak.bed")
! head {table_peak}
chr9 6015447 6015882 peak62341 3027 . 29.11372 312.26147 302.77042 210
chr19 10027662 10028051 peak30656 3015 . 29.01156 310.75055 301.56052 200
chr5 168486223 168486709 peak51278 2920 . 27.98132 299.79123 292.07101 184
chr3 93470271 93470886 peak44388 2688 . 23.79757 276.11172 268.88312 233
chr17 59565331 59565789 peak27510 2593 . 24.16347 266.44458 259.33734 224
chr1 50720506 50720844 peak2756 2492 . 25.26958 256.13898 249.21376 166
chr7 155069957 155070335 peak59492 2442 . 27.61181 251.12788 244.27632 173
chr1 148522501 148523033 peak4345 2362 . 28.98589 243.01486 236.26180 182
chr11 47552717 47553441 peak11765 2350 . 20.41753 241.80923 235.08012 476
chr6 33788819 33789378 peak53313 2323 . 19.06412 239.08537 232.39090 379
[5]:
# Align genomic coordinates from the narrowPeak file to the Human-Cistrome-6k dataset regions
from chrombert.scripts.chrombert_make_dataset import get_overlap
df_supervised = get_overlap(
supervised = table_peak, # a narrowPeak file
regions = os.path.join(basedir, "config", "hg38_6k_1kb_region.bed"),
no_filter = True,
).assign(label = lambda df: df["label"] > 0 )
df_supervised
[5]:
| chrom | start | end | build_region_index | label | |
|---|---|---|---|---|---|
| 0 | chr1 | 10000 | 11000 | 0 | False |
| 1 | chr1 | 16000 | 17000 | 1 | False |
| 2 | chr1 | 17000 | 18000 | 2 | False |
| 3 | chr1 | 29000 | 30000 | 3 | False |
| 4 | chr1 | 30000 | 31000 | 4 | False |
| ... | ... | ... | ... | ... | ... |
| 2137889 | chrY | 26671000 | 26672000 | 2137889 | False |
| 2137890 | chrY | 56674000 | 56675000 | 2137890 | False |
| 2137891 | chrY | 56678000 | 56679000 | 2137891 | False |
| 2137892 | chrY | 56684000 | 56685000 | 2137892 | False |
| 2137893 | chrY | 56685000 | 56686000 | 2137893 | False |
2137894 rows × 5 columns
[6]:
tmpdir = pathlib.Path("tmp_prompt")
tmpdir.mkdir(exist_ok = True)
df_supervised_sampled = df_supervised.query("chrom == 'chr1' ").groupby("label").sample(1000, random_state = 0)
supervised_file = tmpdir / "supervised.csv"
df_supervised_sampled.to_csv(supervised_file,index = False)
df_supervised_sampled # we have `label` column now, but for prediction, we don't need it
[6]:
| chrom | start | end | build_region_index | label | |
|---|---|---|---|---|---|
| 172348 | chr1 | 234585000 | 234586000 | 172348 | False |
| 61761 | chr1 | 72634000 | 72635000 | 61761 | False |
| 102644 | chr1 | 150939000 | 150940000 | 102644 | False |
| 67475 | chr1 | 80752000 | 80753000 | 67475 | False |
| 141933 | chr1 | 199549000 | 199550000 | 141933 | False |
| ... | ... | ... | ... | ... | ... |
| 44233 | chr1 | 51661000 | 51662000 | 44233 | True |
| 127936 | chr1 | 181166000 | 181167000 | 127936 | True |
| 36987 | chr1 | 42825000 | 42826000 | 36987 | True |
| 115176 | chr1 | 165829000 | 165830000 | 115176 | True |
| 116822 | chr1 | 167820000 | 167821000 | 116822 | True |
2000 rows × 5 columns
[7]:
# Create the dataset configuration with preset parameters for DNase-seq data.
dc = chrombert.get_preset_dataset_config(
"prompt_cistrome",
supervised_file = str(supervised_file),
batch_size = 1,
prompt_regulator = "maz", # factors to predict
prompt_celltype = "dnase:k562", # cell type specific cistrome. you can use other cistromes such "h3k27ac:gm12878" for specific target and maybe better, but dnase is recommended for general purpose
)
print(dc)
update path: hdf5_file = hg38_6k_1kb.hdf5
update path: meta_file = config/hg38_6k_meta.json
{
"hdf5_file": "/home/yangdongxu/.cache/chrombert/data/hg38_6k_1kb.hdf5",
"supervised_file": "tmp_prompt/supervised.csv",
"kind": "PromptDataset",
"meta_file": "/home/yangdongxu/.cache/chrombert/data/config/hg38_6k_meta.json",
"ignore": false,
"ignore_object": null,
"batch_size": 1,
"num_workers": 20,
"shuffle": false,
"pin_memory": true,
"perturbation": false,
"perturbation_object": null,
"perturbation_value": 0,
"prompt_kind": "cistrome",
"prompt_regulator": "maz",
"prompt_regulator_cache_file": null,
"prompt_celltype": "dnase:k562",
"prompt_celltype_cache_file": null,
"prompt_regulator_cache_pin_memory": false,
"prompt_regulator_cache_limit": 3,
"fasta_file": null,
"flank_window": 0
}
[8]:
# initialize dataset
ds = dc.init_dataset()
ds[1]
[8]:
{'input_ids': tensor([6, 6, 6, ..., 6, 5, 6], dtype=torch.int8),
'position_ids': tensor([ 1, 2, 3, ..., 6389, 6390, 6391]),
'region': tensor([ 1, 72634000, 72635000], dtype=torch.int32),
'build_region_index': 61761,
'label': False,
'prompts_cell': tensor([0, 0, 0, ..., 0, 0, 0]),
'prompts_all': tensor([1, 1, 1, ..., 1, 1, 1]),
'prompts_regulator': tensor([0, 0, 0, ..., 0, 0, 0]),
'cell': 'dnase:k562',
'regulator': 'maz'}
forward¶
[9]:
dl = dc.init_dataloader()
list_regions = []
list_logits = []
list_indices = []
list_labels = []
with torch.no_grad():
for batch in tqdm(dl):
for k,v in batch.items():
if isinstance(v, torch.Tensor):
batch[k] = v.cuda()
logit = model(batch).float().cpu()
list_regions.append(batch["region"].cpu())
list_logits.append(logit)
list_indices.append(batch["build_region_index"].cpu())
list_labels.append(batch["label"].cpu())
100%|██████████| 2000/2000 [00:48<00:00, 40.84it/s]
[10]:
logit = torch.cat(list_logits).float().numpy()
regions = torch.cat(list_regions).numpy()
indices = torch.cat(list_indices).numpy()
labels = torch.cat(list_labels).numpy()
df_predict_1 = pd.DataFrame(regions, columns = ["chrom", "start", "end"])
df_predict_1["build_region_index"] = indices
df_predict_1["label"] = labels
df_predict_1["logit"] = logit
df_predict_1["prob"] = torch.sigmoid(torch.tensor(logit)).numpy()
df_predict_1
[10]:
| chrom | start | end | build_region_index | label | logit | prob | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 234585000 | 234586000 | 172348 | False | -2.937500 | 0.050331 |
| 1 | 1 | 72634000 | 72635000 | 61761 | False | -5.531250 | 0.003945 |
| 2 | 1 | 150939000 | 150940000 | 102644 | False | -4.656250 | 0.009413 |
| 3 | 1 | 80752000 | 80753000 | 67475 | False | -5.531250 | 0.003945 |
| 4 | 1 | 199549000 | 199550000 | 141933 | False | -4.531250 | 0.010653 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 1995 | 1 | 51661000 | 51662000 | 44233 | True | -2.593750 | 0.069542 |
| 1996 | 1 | 181166000 | 181167000 | 127936 | True | -0.859375 | 0.297470 |
| 1997 | 1 | 42825000 | 42826000 | 36987 | True | -1.179688 | 0.235108 |
| 1998 | 1 | 165829000 | 165830000 | 115176 | True | -0.835938 | 0.302391 |
| 1999 | 1 | 167820000 | 167821000 | 116822 | True | -0.789062 | 0.312370 |
2000 rows × 7 columns
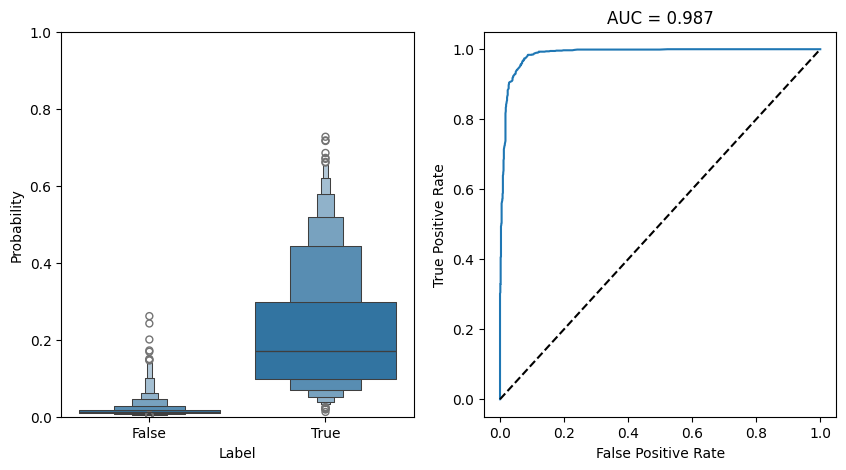
Below we validate the model’s performance by examining prediction probabilities and ROC curves.
[11]:
fig, axs = plt.subplots(1,2, figsize = (10,5))
ax = axs[0]
sns.boxenplot(data = df_predict_1, x = "label", y = "prob", ax = ax)
ax.set_ylabel("Probability")
ax.set_xlabel("Label")
ax.set_ylim(0,1)
ax = axs[1]
fpr, tpr, _ = sklearn.metrics.roc_curve(df_predict_1["label"], df_predict_1["prob"])
auc = sklearn.metrics.auc(fpr, tpr)
ax.plot(fpr, tpr, label = f"AUC = {auc:.3f}")
ax.plot([0,1],[0,1], linestyle = "--", color = "black")
ax.set_title(f"AUC = {auc:.3f}")
ax.set_xlabel("False Positive Rate")
ax.set_ylabel("True Positive Rate")
fig.show()
Cached File¶
Since prompt imputation is resource-intensive, we provide a cache file to simplify this process.
To use it, set prompt_regulator_cache_file and prompt_celltype_cache_file to the path of the cache file.
A sample cache file containing data for seven regulators on chromosome 1 is available at ~/.cache/chrombert/data.
For large-scale prompt imputation, you can use the provided scripts to generate a cache file tailored to your own data.
[12]:
# Initialize model config - prompt_dnase and prompt_cistrome are equivalent configurations
mc = chrombert.get_preset_model_config("prompt_dnase", dropout = 0)
model = mc.init_model().cuda().bfloat16().eval()
# Initialize dataset config with cached prompts
dc = chrombert.get_preset_dataset_config(
"prompt_dnase", # Uses cached prompt files for faster loading
supervised_file = str(supervised_file),
batch_size = 128, # Larger batch size possible since data loading is the bottleneck
prompt_regulator = "maz", # Target transcription factor to predict
prompt_celltype = "dnase:k562", # Cell-type-specific prompt from DNase-seq data used in the pretraining of ChromBERT
)
ds = dc.init_dataset()
ds[1].keys()
update path: pretrain_ckpt = checkpoint/hg38_6k_1kb_pretrain.ckpt
update path: finetune_ckpt = checkpoint/hg38_6k_1kb_prompt_cistrome.ckpt
use organisim hg38; max sequence length is 6391
Loading checkpoint from /home/yangdongxu/.cache/chrombert/data/checkpoint/hg38_6k_1kb_prompt_cistrome.ckpt
Loading from pl module, remove prefix 'model.'
Loaded 112/112 parameters
update path: hdf5_file = hg38_6k_1kb.hdf5
update path: meta_file = config/hg38_6k_meta.json
update path: prompt_regulator_cache_file = cache/hg38_6k_1kb_regulator_prompt_chr1_cache.h5
update path: prompt_celltype_cache_file = cache/hg38_6k_1kb_cistrome_cell_prompt_chr1_cache.h5
[12]:
dict_keys(['build_region_index', 'label', 'emb_cell', 'emb_regulator', 'emb_all', 'cell', 'regulator'])
cache file structure¶
regions: Stores region informationall: Stores region embeddingsemb: A group containing embeddings for each regulator
The cell type cache file has the following structure:
regions: Stores region informationemb: A group containing embeddings for cell type-specific prompts
[13]:
!h5ls {dc.prompt_regulator_cache_file}
all Dataset {183983/Inf, 768}
emb Group
region Dataset {183983/Inf, 4}
[14]:
!h5ls {dc.prompt_regulator_cache_file}/emb
mafk Dataset {183983/Inf, 768}
maz Dataset {183983/Inf, 768}
nfya Dataset {183983/Inf, 768}
nfyb Dataset {183983/Inf, 768}
nipbl Dataset {183983/Inf, 768}
srebf1 Dataset {183983/Inf, 768}
zkscan1 Dataset {183983/Inf, 768}
[15]:
!h5ls {dc.prompt_celltype_cache_file}
emb Group
region Dataset {183983/Inf, 4}
[16]:
!h5ls {dc.prompt_celltype_cache_file}/emb
dnase:a549 Dataset {183983/Inf, 768}
dnase:gm12878 Dataset {183983/Inf, 768}
dnase:hct116 Dataset {183983/Inf, 768}
dnase:helas3 Dataset {183983/Inf, 768}
dnase:hepg2 Dataset {183983/Inf, 768}
dnase:k562 Dataset {183983/Inf, 768}
dnase:mcf7 Dataset {183983/Inf, 768}
forward¶
[17]:
batch.keys()
[17]:
dict_keys(['input_ids', 'position_ids', 'region', 'build_region_index', 'label', 'prompts_cell', 'prompts_all', 'prompts_regulator', 'cell', 'regulator'])
[18]:
dl = dc.init_dataloader()
list_regions = []
list_logits = []
list_indices = []
list_labels = []
with torch.no_grad():
for batch in tqdm(dl):
for k,v in batch.items():
if isinstance(v, torch.Tensor):
batch[k] = v.cuda()
logit = model(batch).float().cpu()
# list_regions.append(batch["region"].cpu())
list_logits.append(logit)
list_indices.append(batch["build_region_index"].cpu())
list_labels.append(batch["label"].cpu())
100%|██████████| 16/16 [00:02<00:00, 5.64it/s]
[19]:
logit = torch.cat(list_logits).float().numpy()
indices = torch.cat(list_indices).numpy()
labels = torch.cat(list_labels).numpy()
df_predict_2 = pd.DataFrame()
df_predict_2["build_region_index"] = indices
df_predict_2["label"] = labels
df_predict_2["logit"] = logit
df_predict_2["prob"] = torch.sigmoid(torch.tensor(logit)).numpy()
df_predict_2
[19]:
| build_region_index | label | logit | prob | |
|---|---|---|---|---|
| 0 | 172348 | False | -2.953125 | 0.049589 |
| 1 | 61761 | False | -5.531250 | 0.003945 |
| 2 | 102644 | False | -4.656250 | 0.009413 |
| 3 | 67475 | False | -5.531250 | 0.003945 |
| 4 | 141933 | False | -4.500000 | 0.010987 |
| ... | ... | ... | ... | ... |
| 1995 | 44233 | True | -2.578125 | 0.070560 |
| 1996 | 127936 | True | -0.863281 | 0.296654 |
| 1997 | 36987 | True | -1.171875 | 0.236516 |
| 1998 | 115176 | True | -0.839844 | 0.301568 |
| 1999 | 116822 | True | -0.785156 | 0.313210 |
2000 rows × 4 columns
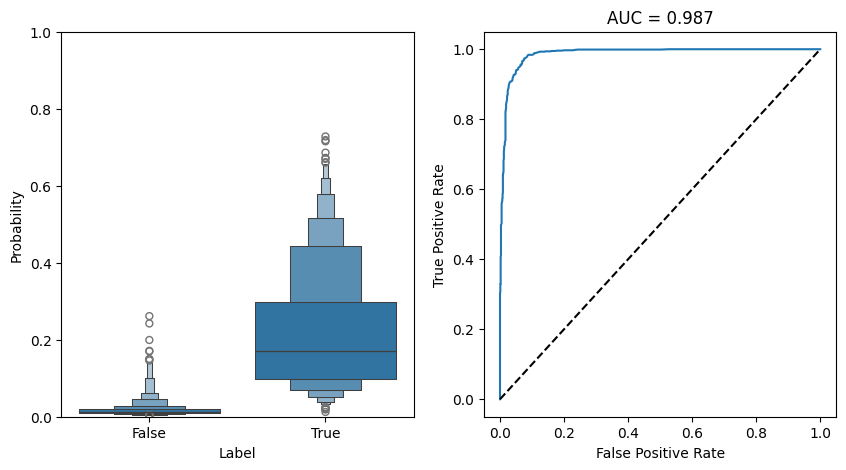
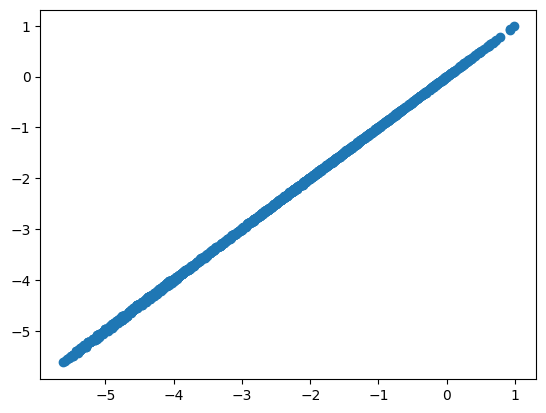
As demonstrated, using a cached file significantly accelerates the prompt imputation process while maintaining comparable performance, with minimal to no differences resulting from precision conversion.
[20]:
fig, axs = plt.subplots(1,2, figsize = (10,5))
ax = axs[0]
sns.boxenplot(data = df_predict_2, x = "label", y = "prob", ax = ax)
ax.set_ylabel("Probability")
ax.set_xlabel("Label")
ax.set_ylim(0,1)
ax = axs[1]
fpr, tpr, _ = sklearn.metrics.roc_curve(df_predict_2["label"], df_predict_2["prob"])
auc = sklearn.metrics.auc(fpr, tpr)
ax.plot(fpr, tpr, label = f"AUC = {auc:.3f}")
ax.plot([0,1],[0,1], linestyle = "--", color = "black")
ax.set_title(f"AUC = {auc:.3f}")
ax.set_xlabel("False Positive Rate")
ax.set_ylabel("True Positive Rate")
fig.show()
[21]:
assert all(df_predict_1["build_region_index"] == df_predict_2["build_region_index"])
plt.scatter(df_predict_1["logit"], df_predict_2["logit"])
[21]:
<matplotlib.collections.PathCollection at 0x7f6d44330790>
RNA-seq prompt enhanced ChromBERT¶
To enhance ChromBERT, we use the RNA-seq prompt from scGPT.
prepare model¶
The model loading process is similar to before, but uses the prompt_exp preset instead. This preset loads a checkpoint that was fine-tuned using scGPT embeddings derived from bulk RNA-seq data.
[22]:
mc = chrombert.get_preset_model_config("prompt_exp", dropout = 0)
model = mc.init_model().cuda().bfloat16().eval()
mc
update path: pretrain_ckpt = checkpoint/hg38_6k_1kb_pretrain.ckpt
update path: finetune_ckpt = checkpoint/hg38_6k_1kb_prompt_expression.ckpt
use organisim hg38; max sequence length is 6391
Loading checkpoint from /home/yangdongxu/.cache/chrombert/data/checkpoint/hg38_6k_1kb_prompt_expression.ckpt
Loading from pl module, remove prefix 'model.'
Loaded 126/126 parameters
[22]:
ChromBERTFTConfig:
{
"genome": "hg38",
"task": "prompt",
"dim_output": 1,
"mtx_mask": null,
"dropout": 0,
"pretrain_ckpt": "/home/yangdongxu/.cache/chrombert/data/checkpoint/hg38_6k_1kb_pretrain.ckpt",
"finetune_ckpt": "/home/yangdongxu/.cache/chrombert/data/checkpoint/hg38_6k_1kb_prompt_expression.ckpt",
"ignore": false,
"ignore_index": [
null,
null
],
"gep_flank_window": 4,
"gep_parallel_embedding": false,
"gep_gradient_checkpoint": false,
"gep_zero_inflation": false,
"prompt_kind": "expression",
"prompt_dim_external": 512,
"dnabert2_ckpt": null
}
[23]:
summary(model)
[23]:
================================================================================
Layer (type:depth-idx) Param #
================================================================================
ChromBERTPrompt --
├─ChromBERT: 1-1 --
│ └─BERTEmbedding: 2-1 --
│ │ └─TokenEmbedding: 3-1 7,680
│ │ └─PositionalEmbedding: 3-2 4,909,056
│ │ └─Dropout: 3-3 --
│ └─ModuleList: 2-2 --
│ │ └─EncoderTransformerBlock: 3-4 6,497,280
│ │ └─EncoderTransformerBlock: 3-5 6,497,280
│ │ └─EncoderTransformerBlock: 3-6 6,497,280
│ │ └─EncoderTransformerBlock: 3-7 6,497,280
│ │ └─EncoderTransformerBlock: 3-8 6,497,280
│ │ └─EncoderTransformerBlock: 3-9 6,497,280
│ │ └─EncoderTransformerBlock: 3-10 6,497,280
│ │ └─EncoderTransformerBlock: 3-11 6,497,280
├─AdapterExternalEmb: 1-2 --
│ └─ResidualBlock: 2-3 --
│ │ └─Linear: 3-12 393,984
│ │ └─Linear: 3-13 590,592
│ │ └─LayerNorm: 3-14 1,536
│ │ └─Linear: 3-15 393,984
│ │ └─Dropout: 3-16 --
│ └─ResidualBlock: 2-4 --
│ │ └─Linear: 3-17 590,592
│ │ └─Linear: 3-18 590,592
│ │ └─LayerNorm: 3-19 1,536
│ │ └─Sequential: 3-20 --
│ │ └─Dropout: 3-21 --
├─PromptsEmb: 1-3 --
│ └─Pooling: 2-5 --
├─PromptHeader: 1-4 --
│ └─Sequential: 2-6 --
│ │ └─ResidualBlock: 3-22 10,626,048
│ │ └─ResidualBlock: 3-23 4,132,608
│ │ └─ResidualBlock: 3-24 1,182,720
│ │ └─ResidualBlock: 3-25 102,720
│ │ └─Linear: 3-26 65
================================================================================
Total params: 75,501,953
Trainable params: 75,501,953
Non-trainable params: 0
================================================================================
prepare dataset¶
The cell embeddings generated by scGPT are stored in a .pkl file, and the regulator embedding cache will be used for our analysis.
[24]:
dc = chrombert.get_preset_dataset_config(
"prompt_exp",
supervised_file = str(supervised_file),
batch_size = 1,
prompt_regulator = "maz", # target of prediction
prompt_celltype = "k562", # cell type of RNA-seq prompt. Must be key in the provided cache file.
)
print(dc)
update path: hdf5_file = hg38_6k_1kb.hdf5
update path: meta_file = config/hg38_6k_meta.json
update path: prompt_regulator_cache_file = cache/hg38_6k_1kb_regulator_prompt_chr1_cache.h5
update path: prompt_celltype_cache_file = cache/hg38_6k_1kb_expression_cell_prompt_cache.pkl
{
"hdf5_file": "/home/yangdongxu/.cache/chrombert/data/hg38_6k_1kb.hdf5",
"supervised_file": "tmp_prompt/supervised.csv",
"kind": "PromptDataset",
"meta_file": "/home/yangdongxu/.cache/chrombert/data/config/hg38_6k_meta.json",
"ignore": false,
"ignore_object": null,
"batch_size": 1,
"num_workers": 20,
"shuffle": false,
"pin_memory": true,
"perturbation": false,
"perturbation_object": null,
"perturbation_value": 0,
"prompt_kind": "expression",
"prompt_regulator": "maz",
"prompt_regulator_cache_file": "/home/yangdongxu/.cache/chrombert/data/cache/hg38_6k_1kb_regulator_prompt_chr1_cache.h5",
"prompt_celltype": "k562",
"prompt_celltype_cache_file": "/home/yangdongxu/.cache/chrombert/data/cache/hg38_6k_1kb_expression_cell_prompt_cache.pkl",
"prompt_regulator_cache_pin_memory": false,
"prompt_regulator_cache_limit": 3,
"fasta_file": null,
"flank_window": 0
}
[25]:
with open(dc.prompt_celltype_cache_file,"rb") as f:
tmp = pickle.load(f)
print(tmp.keys())
print(tmp["k562"].shape)
dict_keys(['a172', 'a375', 'a549', 'a673', 'ag04450', 'be2c', 'bj', 'caco2', 'caki2', 'calu3', 'daoy', 'g401', 'gm12878', 'gm12891', 'gm12892', 'h1', 'h4', 'h7', 'h9', 'hct116', 'helas3', 'hepg2', 'ht1080', 'ht29', 'hues64', 'imr90', 'k562', 'karpas422', 'lhcnm2', 'm059j', 'mcf10a', 'mcf7', 'mg63', 'ncih460', 'ocily7', 'panc1', 'pc3', 'pc9', 'pfsk1', 'rpmi7951', 'sjcrh30', 'sjsa1', 'skmel5', 'sknsh', 'u87mg'])
(512,)
[26]:
dl = dc.init_dataloader()
list_regions = []
list_logits = []
list_indices = []
list_labels = []
with torch.no_grad():
for batch in tqdm(dl):
for k,v in batch.items():
if isinstance(v, torch.Tensor):
batch[k] = v.cuda()
logit = model(batch).float().cpu()
list_logits.append(logit)
list_indices.append(batch["build_region_index"].cpu())
list_labels.append(batch["label"].cpu())
100%|██████████| 2000/2000 [00:13<00:00, 146.07it/s]
[27]:
logit = torch.cat(list_logits).float().numpy()
indices = torch.cat(list_indices).numpy()
labels = torch.cat(list_labels).numpy()
df_predict_3 = pd.DataFrame()
df_predict_3["build_region_index"] = indices
df_predict_3["label"] = labels
df_predict_3["logit"] = logit
df_predict_3["prob"] = torch.sigmoid(torch.tensor(logit)).numpy()
df_predict_3
[27]:
| build_region_index | label | logit | prob | |
|---|---|---|---|---|
| 0 | 172348 | False | -3.312500 | 0.035145 |
| 1 | 61761 | False | -5.718750 | 0.003273 |
| 2 | 102644 | False | -4.781250 | 0.008316 |
| 3 | 67475 | False | -5.562500 | 0.003824 |
| 4 | 141933 | False | -4.812500 | 0.008062 |
| ... | ... | ... | ... | ... |
| 1995 | 44233 | True | -3.375000 | 0.033086 |
| 1996 | 127936 | True | -1.070312 | 0.255344 |
| 1997 | 36987 | True | -3.187500 | 0.039639 |
| 1998 | 115176 | True | -0.835938 | 0.302391 |
| 1999 | 116822 | True | -1.500000 | 0.182426 |
2000 rows × 4 columns
[28]:
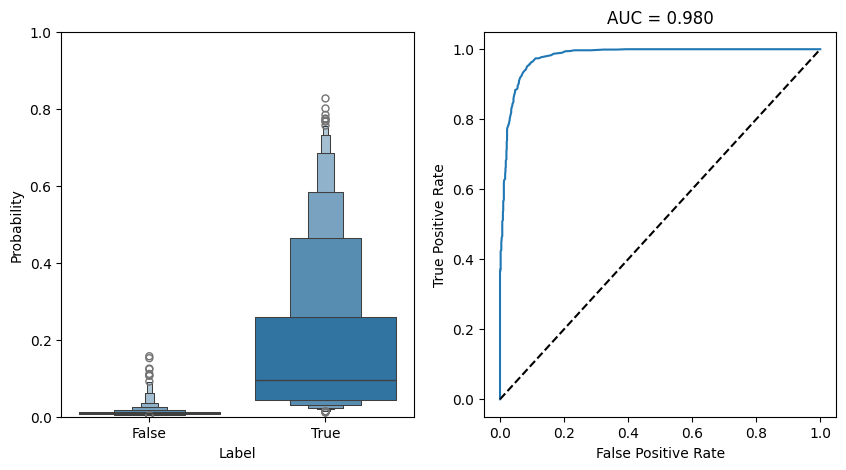
fig, axs = plt.subplots(1,2, figsize = (10,5))
ax = axs[0]
sns.boxenplot(data = df_predict_3, x = "label", y = "prob", ax = ax)
ax.set_ylabel("Probability")
ax.set_xlabel("Label")
ax.set_ylim(0,1)
ax = axs[1]
fpr, tpr, _ = sklearn.metrics.roc_curve(df_predict_3["label"], df_predict_3["prob"])
auc = sklearn.metrics.auc(fpr, tpr)
ax.plot(fpr, tpr, label = f"AUC = {auc:.3f}")
ax.plot([0,1],[0,1], linestyle = "--", color = "black")
ax.set_title(f"AUC = {auc:.3f}")
ax.set_xlabel("False Positive Rate")
ax.set_ylabel("True Positive Rate")
fig.show()
Single-cell prompt enhanced ChromBERT¶
Generating single-cell cistromes using the scGPT cell prompt follows the same procedure as for bulk-level data.
For convenience, we support datasets in H5 format, which include cell and regions tables for prediction. The cell table contains cell names corresponding to keys in the cell prompt cache file.
The regions table includes four columns: chrom, start, end, and build_region_index, which can be inferred from the previously imputed datasets.
[29]:
supervised_file = os.path.join(basedir, "demo","prompt_imputation", "pbmc10k.h5")
!h5ls {supervised_file}
cell Dataset {9629}
regions Dataset {13480, 4}
[30]:
dc = chrombert.get_preset_dataset_config(
"prompt_exp_pbmc", # it uses `prompt_celltype` cache we provided
supervised_file = supervised_file,
batch_size = 1024,
num_workers = 32,
prompt_regulator = "maz", # factors to predict
)
print(dc)
update path: hdf5_file = hg38_6k_1kb.hdf5
update path: meta_file = config/hg38_6k_meta.json
update path: prompt_regulator_cache_file = cache/hg38_6k_1kb_regulator_prompt_chr1_cache.h5
update path: prompt_celltype_cache_file = cache/pbmc10k_scgpt_cell_prompt_cache.pkl
{
"hdf5_file": "/home/yangdongxu/.cache/chrombert/data/hg38_6k_1kb.hdf5",
"supervised_file": "/home/yangdongxu/.cache/chrombert/data/demo/prompt_imputation/pbmc10k.h5",
"kind": "PromptDataset",
"meta_file": "/home/yangdongxu/.cache/chrombert/data/config/hg38_6k_meta.json",
"ignore": false,
"ignore_object": null,
"batch_size": 1024,
"num_workers": 32,
"shuffle": false,
"pin_memory": true,
"perturbation": false,
"perturbation_object": null,
"perturbation_value": 0,
"prompt_kind": "expression",
"prompt_regulator": "maz",
"prompt_regulator_cache_file": "/home/yangdongxu/.cache/chrombert/data/cache/hg38_6k_1kb_regulator_prompt_chr1_cache.h5",
"prompt_celltype": null,
"prompt_celltype_cache_file": "/home/yangdongxu/.cache/chrombert/data/cache/pbmc10k_scgpt_cell_prompt_cache.pkl",
"prompt_regulator_cache_pin_memory": false,
"prompt_regulator_cache_limit": 3,
"fasta_file": null,
"flank_window": 0
}
[31]:
ds = dc.init_dataset()
print(ds[1].keys())
# for each cell, it yields all regions orderly.
print(ds[1]["cell"] == ds[2]["cell"])
print(ds[1]["build_region_index"] == ds[2]["build_region_index"])
dict_keys(['build_region_index', 'emb_cell', 'emb_regulator', 'emb_all', 'cell', 'regulator'])
True
False
[32]:
n_regions = 13480
target_cells = 256 # we just predict limit cells here
num_steps = n_regions/ dc.batch_size * target_cells
list_logits = []
list_indices = []
list_cells = []
# it takes ~10 minutes to run
for i, batch in enumerate(tqdm(dc.init_dataloader(shuffle = False), total = num_steps)):
if i > num_steps:
break
for k,v in batch.items():
if isinstance(v, torch.Tensor):
batch[k] = v.cuda()
with torch.no_grad():
logit = model(batch).float().cpu()
list_indices.append(batch["build_region_index"].cpu())
list_logits.append(logit)
list_cells.append(batch["cell"])
3371it [07:09, 7.85it/s]
[33]:
logit = torch.cat(list_logits).float().numpy()
indices = torch.cat(list_indices).numpy()
cells = np.array(list_cells).flatten()
df_predict_sc = pd.DataFrame()
df_predict_sc["build_region_index"] = indices
df_predict_sc["logit"] = logit
df_predict_sc["prob"] = torch.sigmoid(torch.tensor(logit)).numpy()
df_predict_sc["cell"] = cells
df_predict_sc
[33]:
| build_region_index | logit | prob | cell | |
|---|---|---|---|---|
| 0 | 38 | -1.890625 | 0.131173 | AAACAGCCAATCCCTT-1 |
| 1 | 46 | -1.835938 | 0.137532 | AAACAGCCAATCCCTT-1 |
| 2 | 53 | -2.437500 | 0.080357 | AAACAGCCAATCCCTT-1 |
| 3 | 57 | -4.187500 | 0.014957 | AAACAGCCAATCCCTT-1 |
| 4 | 60 | -3.890625 | 0.020023 | AAACAGCCAATCCCTT-1 |
| ... | ... | ... | ... | ... |
| 3451899 | 10859 | -3.859375 | 0.020646 | AAGCAAGTCATGCTTT-1 |
| 3451900 | 10864 | -3.703125 | 0.024054 | AAGCAAGTCATGCTTT-1 |
| 3451901 | 10945 | -2.984375 | 0.048137 | AAGCAAGTCATGCTTT-1 |
| 3451902 | 10972 | -3.812500 | 0.021615 | AAGCAAGTCATGCTTT-1 |
| 3451903 | 10988 | -3.453125 | 0.030676 | AAGCAAGTCATGCTTT-1 |
3451904 rows × 4 columns
[34]:
df_predict_sc_wide = df_predict_sc.set_index(["build_region_index","cell"])["prob"].unstack().dropna(axis = 1)
df_predict_sc_wide
[34]:
| cell | AAACAGCCAATCCCTT-1 | AAACAGCCAATGCGCT-1 | AAACAGCCACCAACCG-1 | AAACAGCCAGGATAAC-1 | AAACAGCCAGTTTACG-1 | AAACAGCCATCCAGGT-1 | AAACATGCAAGGTCCT-1 | AAACATGCACCGGCTA-1 | AAACATGCACTTGTTC-1 | AAACATGCAGCAAGTG-1 | ... | AAGACATAGGACAACA-1 | AAGACATAGGAGGTTA-1 | AAGACATAGGATTTGC-1 | AAGACATAGTAGGATG-1 | AAGACATAGTTACCGG-1 | AAGACATAGTTATGTG-1 | AAGACCAAGTGTTGCG-1 | AAGACCAAGTTAGACC-1 | AAGACCAAGTTTGGGT-1 | AAGCAAGTCACGCCAA-1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| build_region_index | |||||||||||||||||||||
| 38 | 0.131173 | 0.114369 | 0.119203 | 0.120853 | 0.123366 | 0.139396 | 0.124213 | 0.139396 | 0.122523 | 0.125065 | ... | 0.141281 | 0.128525 | 0.125923 | 0.134776 | 0.133867 | 0.134776 | 0.120853 | 0.128525 | 0.120853 | 0.123366 |
| 46 | 0.137532 | 0.105211 | 0.117572 | 0.117572 | 0.129403 | 0.157137 | 0.120853 | 0.168857 | 0.126785 | 0.128525 | ... | 0.178956 | 0.132964 | 0.130285 | 0.142232 | 0.153042 | 0.145115 | 0.124213 | 0.140336 | 0.120853 | 0.130285 |
| 53 | 0.080357 | 0.072637 | 0.080357 | 0.073696 | 0.078078 | 0.085099 | 0.078078 | 0.078078 | 0.075858 | 0.076961 | ... | 0.083890 | 0.085099 | 0.088820 | 0.082697 | 0.081520 | 0.075858 | 0.082697 | 0.078078 | 0.080357 | 0.080357 |
| 57 | 0.014957 | 0.012432 | 0.014064 | 0.012821 | 0.014504 | 0.015425 | 0.014064 | 0.014504 | 0.013637 | 0.014064 | ... | 0.016915 | 0.015906 | 0.016403 | 0.015425 | 0.016403 | 0.014064 | 0.014957 | 0.014957 | 0.014064 | 0.014957 |
| 60 | 0.020023 | 0.015425 | 0.018264 | 0.016403 | 0.018833 | 0.020332 | 0.018547 | 0.021287 | 0.017442 | 0.017986 | ... | 0.023689 | 0.020964 | 0.021287 | 0.021615 | 0.021948 | 0.019419 | 0.019124 | 0.020646 | 0.018547 | 0.019419 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 183917 | 0.032101 | 0.028008 | 0.030215 | 0.029312 | 0.031144 | 0.032590 | 0.029760 | 0.030215 | 0.030676 | 0.030676 | ... | 0.034100 | 0.032101 | 0.031144 | 0.031619 | 0.032590 | 0.030676 | 0.030215 | 0.031144 | 0.030215 | 0.031619 |
| 183923 | 0.740174 | 0.685950 | 0.704973 | 0.700895 | 0.722527 | 0.762070 | 0.714628 | 0.766294 | 0.709019 | 0.717804 | ... | 0.800692 | 0.744656 | 0.752013 | 0.757794 | 0.773216 | 0.740174 | 0.726426 | 0.749087 | 0.711431 | 0.728748 |
| 183953 | 0.843895 | 0.785309 | 0.818737 | 0.800692 | 0.831143 | 0.867934 | 0.826712 | 0.836555 | 0.822189 | 0.827828 | ... | 0.873215 | 0.850965 | 0.862468 | 0.852935 | 0.860604 | 0.824462 | 0.840783 | 0.843895 | 0.826712 | 0.839734 |
| 183969 | 0.295840 | 0.247987 | 0.281406 | 0.262842 | 0.290176 | 0.309858 | 0.277473 | 0.314051 | 0.268941 | 0.275130 | ... | 0.339828 | 0.309024 | 0.316581 | 0.311532 | 0.325092 | 0.289372 | 0.292595 | 0.304042 | 0.282988 | 0.295840 |
| 183981 | 0.229535 | 0.208179 | 0.216012 | 0.217338 | 0.222700 | 0.242206 | 0.220007 | 0.239349 | 0.222700 | 0.222700 | ... | 0.247987 | 0.228156 | 0.222700 | 0.233706 | 0.235108 | 0.233706 | 0.220007 | 0.228156 | 0.217338 | 0.224055 |
13480 rows × 256 columns
[35]:
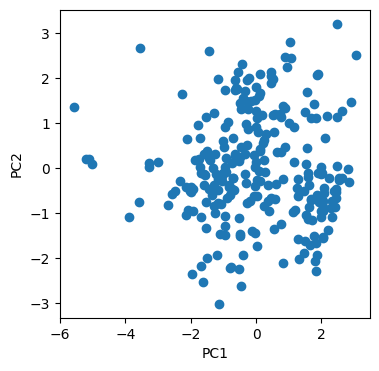
# The predicted probabilities shows heterogeneity of the cells. We use PCA to visualize the cells in 2D space, but UMAP or t-SNE can be used for better visualization.
import sklearn.decomposition
model_pca = sklearn.decomposition.PCA(n_components = 2)
df_predict_sc_pca = model_pca.fit_transform(df_predict_sc_wide.T)
df_predict_sc_pca = pd.DataFrame(df_predict_sc_pca, index = df_predict_sc_wide.columns, columns = ["PC1", "PC2"])
fig, ax = plt.subplots(1,1,figsize= (4,4))
ax.scatter(df_predict_sc_pca["PC1"], df_predict_sc_pca["PC2"])
ax.set_xlabel("PC1")
ax.set_ylabel("PC2")
fig.show()
Fine-tuning¶
We use the same fine-tuning strategy as for other tasks, but with a different dataset. The fine-tuning dataset is in HDF5 (.h5) format and is similar to the one used for single-cell cistrome imputation.
It should include two additional tables: regulators and label.
The
regulatorstable must have the same length as thecelltable to ensure proper pairing.The
labeltable should have rows corresponding toregionsand columns corresponding toregulatorsandcell.
For practical fine-tuning use cases, please refer to the code.